您的位置:首页 > 文学文学
文学教育中的“人机协同”如何可能?
2024-08-13人已围观
我将从“术”的层面出发,分享一些“人机协同”的课堂案例。案例共有四个,都源于我的课堂教学经验或即将付诸实践的教学构想。我想借此机会抛砖引玉,也恳请大家批评建议。
林莹在工作坊上发言。
第一个案例与一个字有关。我在大学语文课堂上会涉及汉字结构和生成方式的介绍。在刚刚过去的春季学期,我是以“春”字来举例的。在正式讲解这个字前,我预留了半分钟时间给同学们思考,思考的内容是,假如穿越到几千年前的造字现场,你会怎么创造“春”字,什么因素是一定要呈现出来的?从此刻开始,距离答案揭晓也大概有半分钟时间,诸位听众可以同步思考一下。

紧接着,我在课堂上请出Chat-GPT来作答。我往对话框敲入指令,请它描述春天到来的标志。Chat-GPT很快给出了五条标准,其中前两条是“温暖的气温”和“绿色的新叶”。这个答案基本是与我们的第一反应相吻合的。此时我再请同学们回过头来,共同查阅东汉许慎《说文解字》和相关文献的分析。
许慎的说法是,“春,从艹从日,艹春时生也,屯声”;清人段玉裁《说文解字注》与此大同小异:“从日艹屯。日艹屯者,得时艹生也。屯字,象艹木之初生。屯亦声。”二者的关键区别在于,怎么理解“屯”这个部件。许慎认为“屯”是纯粹的声符,段玉裁则提出“屯”同时表音和表义,也就是所谓的“亦声”。
我们将古人的解读与Chat-GPT 的回答相对照:“日”对应于Chat-GPT所说的“温暖的气温”,“艹”和“屯”对应于“绿色的新叶”(见图一高亮色块的对应关系)。在“春”的甲骨文字形里,“艹”分解成了两个“屮”,而“屯”几乎就是植物萌芽(图一右下方)的拟态。不难发现,我们的祖先和AI大模型,虽然被漫长的历史和海量的网络数据分隔在两端,但在描述春天这件事情上是不谋而合的,这很浪漫,又很科学。在这个案例里,AI主要扮演了类似于“智能助教”或“赛博对谈者”的角色。
 第二个案例与一句诗有关。同济大学出版社出版的大学语文教材,收录了苏轼著名的《六月二十日夜渡海》一诗。这首诗的前两联为“参横斗转欲三更,苦雨终风也解晴。云散月明谁点缀,天容海色本澄清。”首句中“参横斗转”一词,教材给的注释是“参、斗:两星宿名。横、转:星宿位置移动”。这个解释固然简洁清晰,但“参横斗转”到底形容何种情形,由于距我们的现代生活过于遥远,学生还是会有一种疏离感,很难真正理解和体认。
第二个案例与一句诗有关。同济大学出版社出版的大学语文教材,收录了苏轼著名的《六月二十日夜渡海》一诗。这首诗的前两联为“参横斗转欲三更,苦雨终风也解晴。云散月明谁点缀,天容海色本澄清。”首句中“参横斗转”一词,教材给的注释是“参、斗:两星宿名。横、转:星宿位置移动”。这个解释固然简洁清晰,但“参横斗转”到底形容何种情形,由于距我们的现代生活过于遥远,学生还是会有一种疏离感,很难真正理解和体认。
鉴于这首诗的写作时间和地点非常明确,如果把时空信息(“地点取今海南省海口市,日期取1100年7月28日”)代入天象模拟软件Stellarium,进行当夜星空的模拟,就会意识到“该时段的参宿位于地平线以下,根本无法观测到,即使后半夜参宿现于夜幕,三星连线也是几乎垂直。”据此可知,当苏轼谈及“参横斗转”时,他并非如以往批评家认为的那样是在写实。在他笔下,“参横斗转”这个词与“与诗中的‘云散月明、天容海色’同为典故”。作为对照的是清人彭孙遹的诗作,他在《三月十五夜月自正月来无日不雨是夜始见月色赋十韵》中写道“天挂欲横参”。据Stellarium显示,在该诗撰写的“1661年4月13日”和“浙江海盐”时空里,彭氏身处的夜晚确有“参横”星象,而且当时是一个“月球被照亮部分占比达到98.8%”的明月之夜,故而所咏情境与诗题所云“自正月来无日不雨,是夜始见月色”相吻合,属于一种主客观上“守得云散见月明”的同步状态。换言之,两首诗所写的“参横”形同而实异。
上述关于案例二的引证、对比、分析和结论,包括引用的文字和图片(图二)资料,均出自刘梦涵《古典诗词“参横”意象的时令规律与审美价值——基于数字人文天象模拟技术的探析》(《数字人文》2023年第1期)一文,这是她本科时期在安徽大学唐宸老师指导下所做的国家级大学生创新创业训练计划项目“古典诗词中的‘参横’意象——基于天象模拟技术的探究”阶段性成果。在这个案例中,大数据虚拟仿真软件作为一种“电子教具”,能够协助授课者将遥远而陌生的术语,“转译”为听课学生切身可感的日常景观。
 我要介绍的第三个案例,与一部小说有关。我为中文系大二学生开设了专业选修课“《红楼梦》研究”。研究《红楼梦》,首要任务之一便是理清书中错综复杂的人物关系。如果请你为《红楼梦》绘制一幅人物关系图,你会怎么来构思呢?一般情况下,我们会基于血缘和亲缘关系来进行绘图。这当然离不开文本细读的功夫,这也是中文系师生的“看家本领”。而与传统的细读(close reading)相对应,AI可以为我们增加新的远读(distant reading)视角。
我要介绍的第三个案例,与一部小说有关。我为中文系大二学生开设了专业选修课“《红楼梦》研究”。研究《红楼梦》,首要任务之一便是理清书中错综复杂的人物关系。如果请你为《红楼梦》绘制一幅人物关系图,你会怎么来构思呢?一般情况下,我们会基于血缘和亲缘关系来进行绘图。这当然离不开文本细读的功夫,这也是中文系师生的“看家本领”。而与传统的细读(close reading)相对应,AI可以为我们增加新的远读(distant reading)视角。
2021年,在华东师范大学情报学专业的一份硕士课程作业中,作者季泽豪尝试运用“自然语言处理、社会网络分析法、信息可视化、数据挖掘等手段”,重新解读《红楼梦》中的人物关系。他“基于共词分析法的基础理论,将红楼梦作品中的每一个段落视为书中人物登场演出的一个舞台,一个共现单元,依此统计角色与角色之间的共现频次或者说交往关系强度”,进而基于段落共现关系,“将实体抽象为节点, 将对象之间的关系抽象为边的形式”,生成复杂网络图谱并进行可视化处理,构建了新式人物关系图(图三)。该图用七种颜色代表“基于模块化算法生成的七大聚类群体”,“节点大小由PageRank算法与加权中心度决定,节点越大,则说明该角色自身及其邻居节点在整体网络中都比较重要,是一种兼顾自身与自身‘朋友圈’的优良算法”(参见季泽豪《这就是读懂红楼梦的DNA密码?——数据话红楼,网络绘人心》,知乎ID“我是万能小滑块”)。
如果说以往的《红楼梦》人物关系图显示了亲缘的、应然的亲疏远近,那么,这份体现出群聚关系和重要程度的新式网状图,则直观呈现了文本的、实然的人物亲疏距离以及人物存在感之强弱。其中最为突出的两个群体分别标注为红色和紫色,一个以贾母、王熙凤为首,另一个以贾宝玉为首。这为读者提供了一个将观察视域从近景推拉至远景的解读路径。不过,关于远景的解读还是应该回归到文本细节,不可仅仅依恃远景而大作阐释。文本细读始终是第一位的,远读虽让我们免于陷入细节的风险,但仍是第二位的、辅助性的。
第四个也是最后一个案例,是我即将付诸实践的一种写作训练构想。据我观察,在我们主流的阅读培养和写作训练中,长期存在着两个畸轻畸重的问题,一是输入方面重虚构作品,轻非虚构作品;二是输出方面重原创型写作,轻改写和仿写。稍后华东师范大学徐俪成老师的发言会涉及仿写问题,他强调了艺术风格和语言特征、辞章手法的对应关系,让学生通过模仿古代作家风格撰写拟作,从中习得作品分析和写作实践的双重能力,对此我深以为然。这里我主要结合“改写”和“非虚构作品”这两点来分享一个教学构想。
这个教学构想缘起于我的教学和育儿经验。我曾经从一位大学新生那里听到一种颇具代表性的自述,那就是,他们经历高考、来到大学,本可以自由阅读了,但接受了漫长的语文应试教育的他们,却像一个个长期营养不良的人,突然面对丰盛的自助大餐,不知道怎么去随心享用。并且,他们肠胃系统早已过度虚弱,即便强行进食,实际上也无福消受。这个描述是很让人心痛的。冰冻三尺非一日之寒,我想,要改变这个局面,就必须将视点前移到更早的节点。因此我给出的药方是,尽早帮助孩子们培养起自主阅读的习惯。那么,从科学的角度来谈,到底几岁可以实现自主阅读呢?这也是我在养育幼儿时遇到的一个疑惑。
英文读物由于有完善的、通行的分级体系,一方面能够通过诸如蓝思值测试这样的便捷方式,快速定位读者的阅读能力,另一方面能够根据分级标准,将已有文本进行分级,或将已有文本改写成其他等级,提供给相应级别的读者。这里所说的“将已有文本改写成其他等级”,包括例如“小猪佩奇”系列故事这样的虚构作品改写(参见图四,这本读物适合英文水平二级的读者自主阅读),也包括例如NASA新闻这样的非虚构作品改写(图五,这篇文章有五种等级可以选择,适应于不同英文水平读者的自主阅读需求。这些改写版本由newsela平台提供,该平台专门改写新闻报道和专题文章,话题涵盖自然、人文、社科等多个领域)。
在有明确分级标准、分级读物又足够丰富的情况下,哪怕是语言水平再低的读者,都有机会找到自己喜欢阅读的、适合自己阅读的文本,自由享受阅读的乐趣。今天上午,平和双语学校的李天蔚老师提到高中生对有些作家作品“不感兴趣”,也枚举了他们“感兴趣”的对象。假如说语文的课堂教育要创造条件让学生喜欢上原本“不感兴趣”的好作家、难作品,那么课外自主阅读,就是要创造条件让学生尽情探索自己“感兴趣”的文本世界。从这点来看,如何为中文分级定级、如何为中文读物改写出从话题到级别都具有足够涵盖面和适应力的版本,就构成了培养幼儿自主阅读习惯(以及推进对外汉语教学)的基础工作之一。
中文分级是一项难度极高的工作。基于中文本身的复杂度和特殊性,我们无法通过简单移植英文分级标准来实现中文的分级。在此情形下,我们不妨反向而为,从改写入手。改写文本,如同前述的仿写工作,本身就是一种可行而有效的写作实践。因此,在我的写作训练构想中,我计划让AI兼任竞争者与协作者。在写作课的其中一个模块里,我制定了这样的教学计划(参见图六)。第一步,让学生选择改写的主题和目标读者——这里的读者可以是自己的弟弟妹妹侄子外甥,也可以是与自己同龄的外国友人;第二步,根据目标读者的阅读兴趣和能力特点,确定具体的改写文本,开始着手人工改写;第三步,选择两种或以上的AI大语言模型上发布改写指令,将AI处理的不同改写版本,与自己的人工改写结果进行对比,最终博采“人”“机”之优长,通过人机协同输出一个较为理想的版本,并将此版本交给目标读者,接受读者的阅读反馈。我希望能借助这样的训练和反馈,一方面帮助写作者调整改写结果,提高语言文字表达的灵活性、精准性和适用性,另一方面也反向协助我们不断积累中文分级的具体指标,从“归纳”的角度,反哺中文读物的分级、定级工作。
讲到这里,我的四个案例就分享完了。我们来回顾一下,第二、三个案例分别以一句诗、一本小说为例,在教学中引入数字人文研究成果,这是一种教学内容上的“人机协同”。随着数字人文这一新兴交叉学科的日益推进,我相信会有越来越多来自学界或自主原创的研究成果,可以引入人文学科的教学现场(我自己也有过一个小小的尝试,参见林莹、施维加《古代小说文献数字化的优化路径探索——一种基于“条件生成对抗网络”(ConGAN)的新方法》,孙超主编《数字人文与古代文学研究》,上海三联书店2023年版)。第一、四个案例,分别以一个字、一种写作训练构想为例,则属于教学手段上的“人机协同”,换句话说,就是让机器充当人类的助教,以此提高教学的效果,让学生更快更好地理解知识产生的思维方式,掌握语言文字的实际运用能力。
上个月初,高考结束后不久,AI也经受了首次高考全卷评测。此次测评仅针对“GPT-4o及在2024年高考前开源的6个模型”展开实验,“因无法确定闭源模型的更新时间,为公平起见,此次评测没有纳入商用闭源模型”。根据测评结果,AI大模型在语文、英语两个科目上的表现尤为亮眼,满分150分的语文答卷,AI大模型的得分可以高达124分(图七,参见《“大模型”出分了!首个AI高考全卷评测结果发布》,“澎湃新闻·澎湃号·政务”栏目,2024-06-19,作者为上海人工智能实验室)。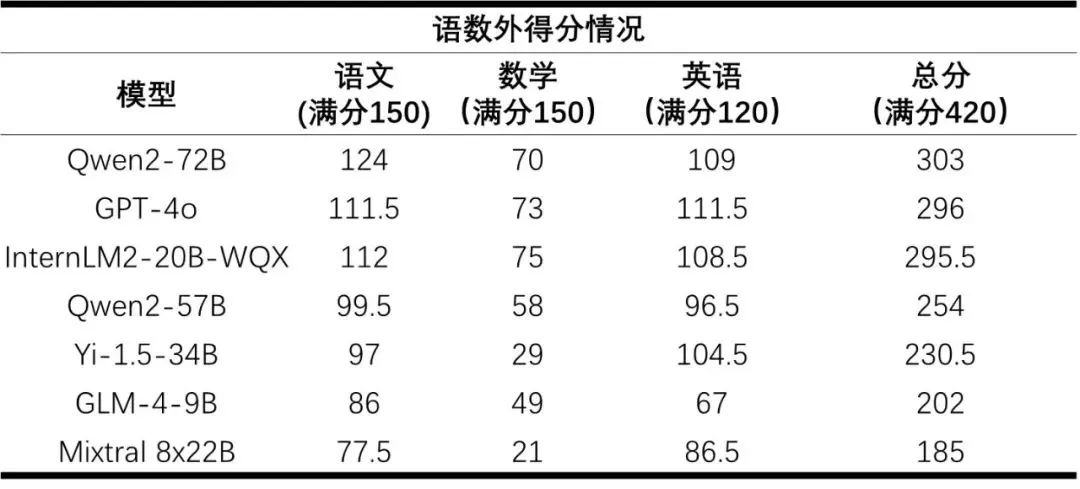
图七 AI大模型高考的“语数外”成绩 图源:上海人工智能实验室Shanghai AI Lab。
在如今人工智能技术日新月异的时代背景之下,单纯传授知识的教学早已意义不大,迟早要被AI取代。比一个个知识点更重要的,自然是知识背后的思维、逻辑和方法,知识之外的情感、观念和洞见,以及运用知识应对具体需求的实操能力。在这些方面,AI无法成为独立的教育者,但可以充当教育者的优质教具和助教。也是在这个意义上,充分强调人之主体性、灵活调用AI功能性的“人机协同”教学法,很有可能在未来的人文教育中持续拓宽应用,施展魅力。
很赞哦! ()
上一篇:返回列表'>谈谈自媒体、新媒体和融媒体
下一篇:AI时代的怀旧魔法:文学正在教育我们什么'>返回列表



